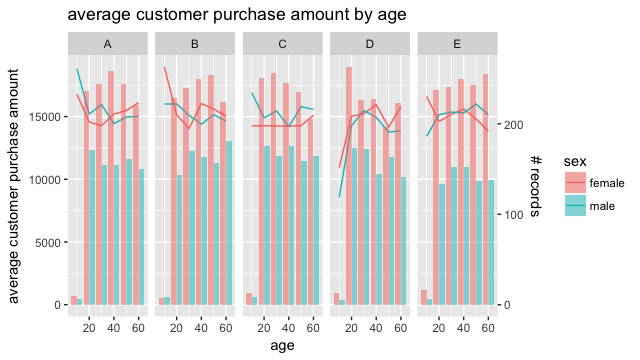
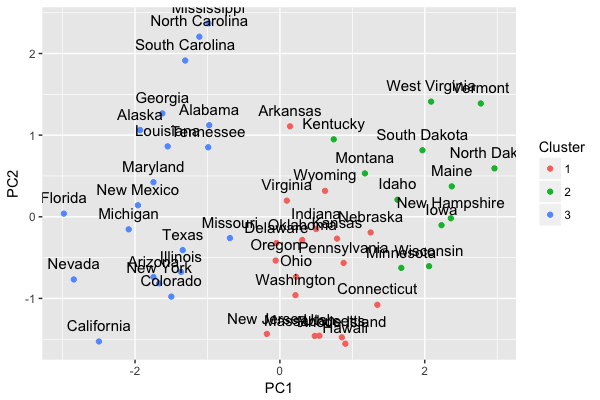
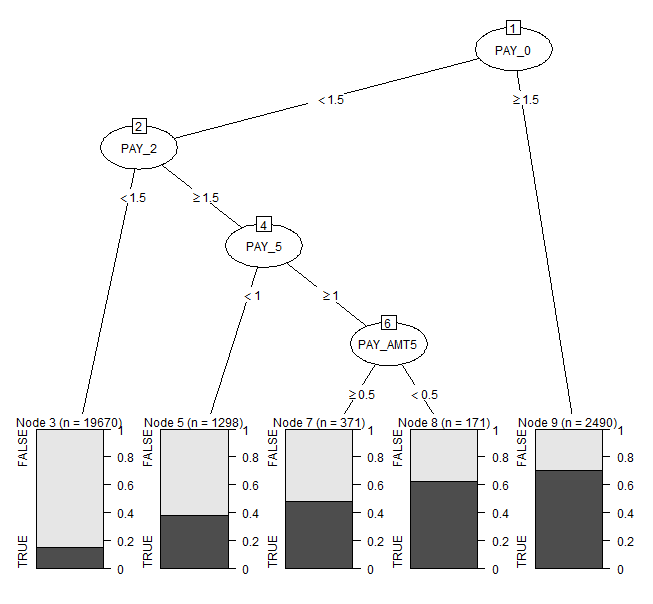
Rでローデータの読み込み(データフレーム、data.table、webデータの取得)
Rを使ったデータ前処理の方法を解説する。 データフレーム形式だけでなく、大きなデータを扱うのに高速なdata.tableを使ったデータの前処理の方法も解説する。 まず一般的にデータの前処理の手順は以下のようなものである。 ローデータの読み込み データの整形(分析用データセットの生成。データの持つ情報は保持) データの型確認 必要な(分析対象とする)列の抽出 列名の変更 データ変換 データの型変換 日時データの生成 因子データの生成(ordered) データクリーニング(正しく分析できるように必要に応じて情報を一部削る) 行の削除(抽出) 行の並べ替え(ソート) 標準化(scale) 欠損値処理…