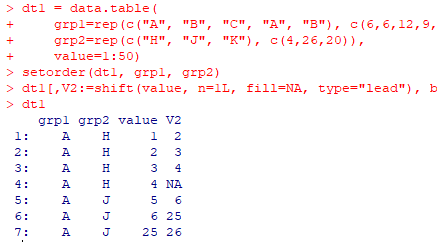
Rにおける代表的な一般化線形モデル(GLM)の実装ライブラリまとめ
一般化線形モデル(GLM)は統計解析のフレームワークとしてとにかく便利。Rでもビルトインの関数から拡張までさまざまなライブラリから提供されている機能だが、さまざまなライブラリがありすぎてどれを使えばいいのかわかりにくいのと、さらに一般化線形モデル(GLM)自体にもいろいろな亜種があるため、どの手法をどのライブラリの関数で実装すればいいかわからなくなる。 そこでRに実装されている代表的なGLM系の関数と特徴についてまとめてみた。 一般化線形モデルのおさらい 一般化線形モデルとは $$ y = g^{-1}(\alpha + \beta_1 x_1 + \beta_2 x_2 + … …